I mitt förra inlägg berättade jag om uppdateringarna som jag införde i dagarna. Vi har nu ett komplext rankingsystem som tittar på en massa olika faktorer för att ranka löparna (förhoppningsvis) korrekt. Men hur vet vi att det faktiskt fungerar?
Ett sätt att mäta hur bra rankingsystemet fungerar är att genom att mäta poängfelet, dvs skillnaden mellan utdelad poäng och åkarens tidigare rankingpoäng för alla resultat i hela databasen. Ett bra rankingsystem borde ju kunna räkna ut en korrekt rankingpoäng, varvid poängfelet vid poängutdelningen borde bli lågt. 
Den som har pluggat sannolikhetslära förstår säkert att det är standardavvikelsen jag pratar om. För den som inte pluggat sannolikhetslära kan jag berätta att genom att beräkna standardavvikelsen för en “hög med tal” kan vi se hur många av talen som ligger inom ett visst spann, och då kan vi också förutsäga hur framtida tal kommer att ligga. Om standardavvikelsen för vårt poängfel är beräknat till t ex 5 betyder det alltså att 68.2% (se bilden ovan) av poängutdelningarna kommer att ligga inom 5 poäng ifrån medeltalet.
Men vänta, stopp ett tag! Gäller det här alltid? För alla talserier och situationer??
Tja, det gäller för normalfördelade talserier, dvs de som följer klock-formen i figuren ovan. Väldigt många situationer i naturen följer faktiskt normalfördelningen riktigt bra. Vi kan titta på hur poängfelet fördelar sig i vårt rankingsystem:
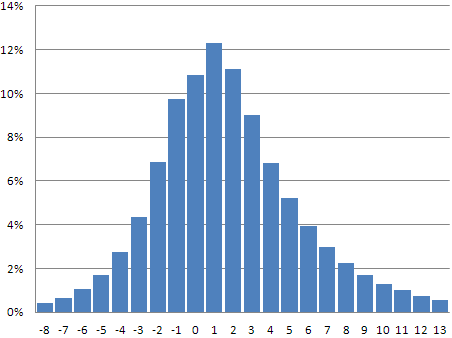
Nämen, vad fint, en tydlig klockform tycker jag mig se! Jag räknar ut att medeltalet av poängfelet blir 1.61 vilket betyder att åkarna generellt får en lite bättre utdelad poäng än vad de hade tidigare. Det känns fullt rimligt och går bra ihop med att åkarna utvecklas och blir bättre med tiden. Standardavvikelsen räknar jag ut till 4.37, vilket alltså betyder att 68.2% av resultaten förutspåddes med ett fel på mindre än 4.37 poäng. Inte så illa egentligen!
Vi kan även titta på hur det såg ut tidigare, för att se om våra förbättringar har gjort någon skillnad:
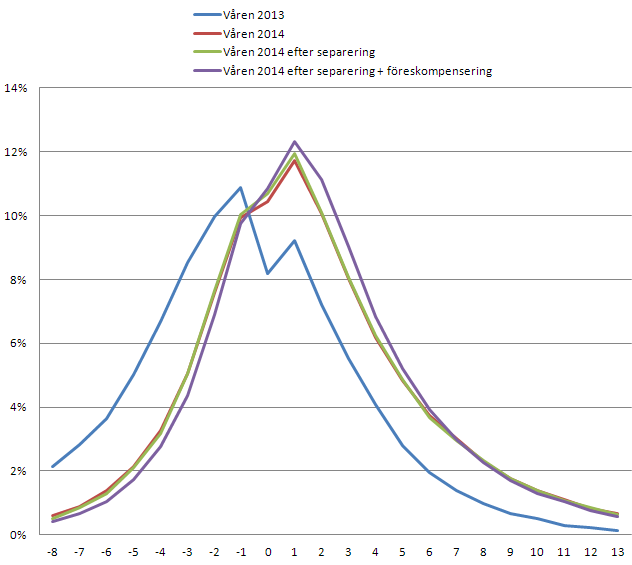
och motsvarande statistikegenskaper var:
- Våren 2013: Std.avv: 5.35, medel: -1.36
- Våren 2014: Std.avv: 4.74, medel: 1.58
- Våren 2014 efter separering av längdskidor/rullskidor: Std.avv: 4.67, medel: 1.62
- Våren 2014 efter separering av längdskidor/rullskidor + föreskompensering: Std.avv: 4.37, medel: 1.61
Jodå, standardavvikelsen har stadigt minskat, så våra förbättringar verkar ha gett effekt! Jag blev lite förvånad över att kurvan från våren 2013 var så vänsterförskjuten, och det känns ju inte bra att ha ett negativt medelvärde för ett rankingsystem. Med facit i hand så var det nog ett klokt val att byta från den gamla rankingalgoritmen.
